A replay on breakfast TV this morning of the well known Panarama hoax (1st April 1957) reminded me of the mission we’re on at Bristol to “turn spaghetti into lasagne”. This mission is number 7 on the JISC 10 pointer list for improving organisational efficiency: spaghetti refers to the proliferation of point-to-point (tightly coupled) integrations between our University’s many IT Systems and lasagne refers to the nicely layered systems and data architecture we’d like to achieve (see elsewhere in this blog).
However, transforming our data architecture overnight is not achievable, instead we’ve developed a roadmap spanning several years in which reform of our data architecture fits into the wider contexts of both Master Data Management and Service Oriented Architecture.
In November last year our senior project approval group (now known as the Systems and Process Investment Board) agreed to resource a one year Master Data Integration Project. We will return to the same board early in 2015 with a follow on business case, but this year’s project is concerned with delivering the following foundation work.
- The establishment of Master Data governance and process at the University (the creation of a Master Data Governance Board and the appointment of Data Managers and Data Stewards as part of existing roles throughout the University – responsible for data quality in their domains and for following newly defined Change of Data processes),
- Completion of documentation of all the spaghetti (aka the integrations between our IT systems) in our Interface Catalogue, and also the documentation of our Master Data Entities (and their attributes and relationships) in an online Enterprise Data Dictionary (developed in-house),
- Development of a SOA blueprint for the University, including our target data architecture. This with the help of a SOA consultant and to inform the follow on business case for SOA at Bristol, which we hope the University will fund from 2015.
We are undertaking this work with the following resources: Enterprise Architect (me) at 0.3FTE for a year, a Business Analyst (trained in Enterprise and Solutions Architecture) at 0.5FTE, a Project Manager at 0.3FTE, IT development time (both for developing the Enterprise Data Dictionary and for helping to populate the Interface Catalogue with information) and approximately £60K of consultancy.
We had some very useful consultancy earlier this year from Intelligent Business Strategies: several insightful conversations with MD, Mike Ferguson, and a week with Henrik Soerensen. From this we were able to draw up a Master Data Governance structure tailored to our organisation, which we are now trialling. 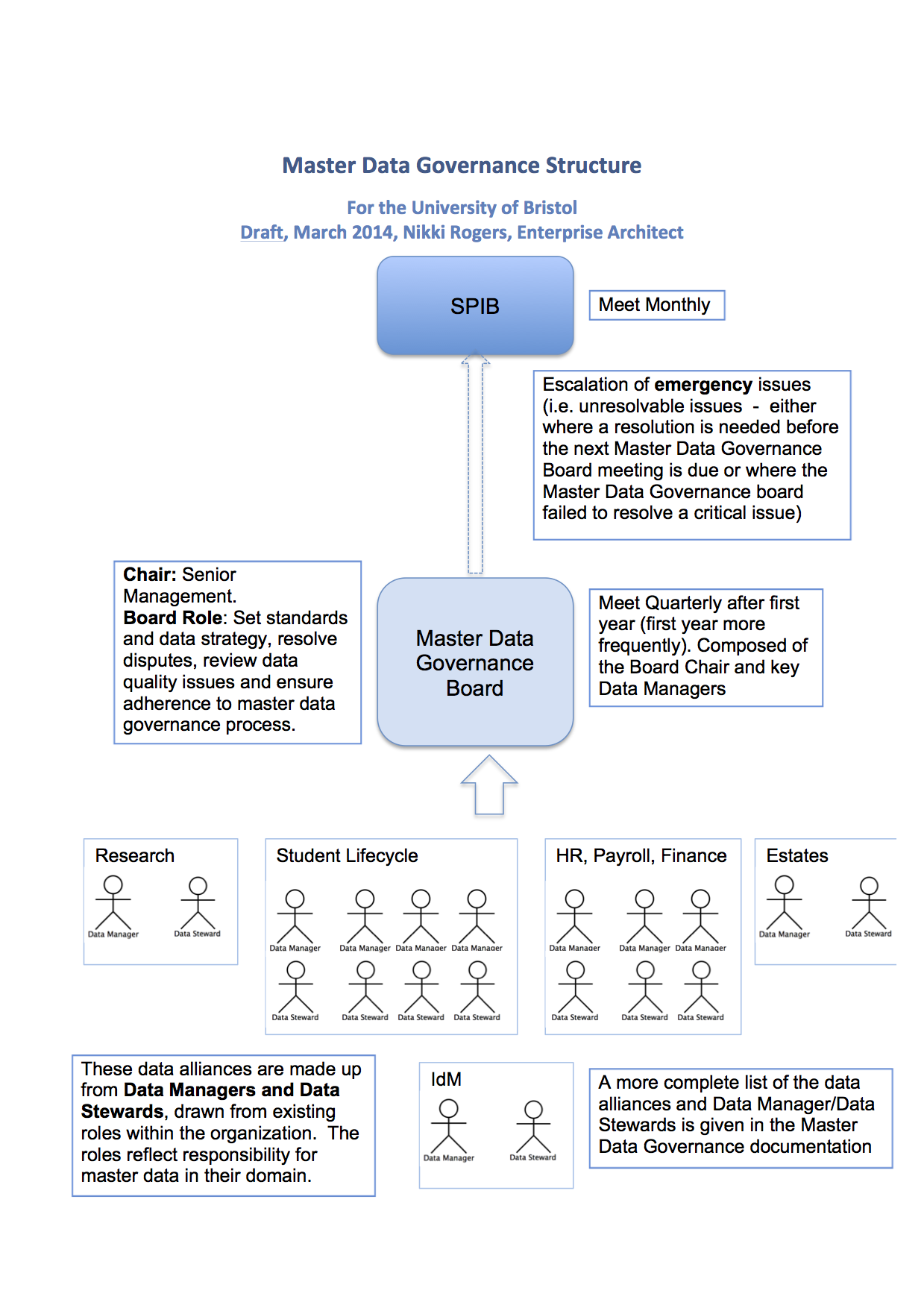
This work also helped us to consider key issues around governance processes and how to capture key information – such as including business rules around data – in the online data dictionary.
Later this year we will be working for an extended period with an independent SOA consultant based in the South West, Ben Wilcock of SOA growers. We have already worked with Ben in small amounts this year and I am very much looking forward to collaborating with him further to develop our target data architecture (most likely a set of master data services, supporting basic CRUD operations) within the context of a SOA blueprint for our enterprise architecture.